

NSF Approves Proposal for Machine Learning Cyberinfrastructure
San Diego, July 27, 2017 — Effective October 1, 2017, Calit2 and the Qualcomm Institute will launch a new NSF-funded community infrastructure in support of machine learning research. Ahead the launch, HPCwire Editor John Russell spoke with Calit2 Director Larry Smarr, PI on the new project, and his co-PI Tom DeFanti. a research scientist in QI, about their plans recently given the green light by NSF. With HPCwire's permission, below is a reprint of an extended excerpt from Russell's July 25 article. To read the full report on the HPCwire website, click on the link at bottom.
Earlier this month, the National Science Foundation issued a $1 million grant to Larry Smarr, director of Calit2, and a group of his colleagues to create a community infrastructure in support of machine learning research. The ambitious plan – Cognitive Hardware and Software Ecosystem, Community Infrastructure (CHASE-CI) – is intended to leverage the high-speed Pacific Research Platform (PRP) and put fast GPU appliances into the hands of researchers to tackle machine learning hardware, software, and architecture issues.

Given the abrupt rise of machine learning and its distinct needs versus traditional FLOPS-dominated HPC, the CHASE-CI effort seems a natural next step in learning how to harness PRP’s high bandwidth for use with big data projects and machine learning. Perhaps not coincidentally Smarr is also principal investigator for PRP. As described in the NSF abstract, CHASE-CI “will build a cloud of hundreds of affordable Graphics Processing Units (GPUs), networked together with a variety of neural network machines to facilitate development of next generation cognitive computing.”
Those are big goals. Last week, Smarr and co-PI Thomas DeFanti spoke with HPCwire about the CHASE-CI project. It has many facets. Hardware, including von Neumann (vN) and non von Neumann (NvN) architectures, software frameworks (e.g., Caffe and TensorFlow), six specific algorithm families (details near the end of the article), and cost containment are all key target areas. In building out PRP, the effort leveraged existing optical networks such as GLIF by building termination devices based on PCs and providing them to research scientists. The new device — dubbed FIONA (Flexible I/O Network Appliances) – was developed by PRP co-PI Philip Papadopoulos and is critical to the new CHASE-CI effort. A little background on PRP may be helpful.

As explained by Smarr, the basic PRP idea was to experiment with a cyberinfrastructure that was appropriate for a broad set of applications using big data that aren’t appropriate for the commodity internet because of the size of the of the datasets. To handle the high speed bandwidth, you need a big bucket at the end of the fiber notes Smarr. FIONAs filled the bill; the devices are stuffed with high performance, high capacity SSDs and high speed NICs but based on the humble and less expensive PC.
“They could take the high data rate without TCP backing up and thereby lowering the overall bandwidth, which traditionally has been a problem if you try to go directly to spinning disk,” says Smarr. Currently, there are on the order of 40 or 50 of these FIONAs deployed across the West Coast. Although 100 gigabit throughput is possible via the fiber, most researchers are getting 10 gigabit, still a big improvement.
DOE tests the PRP performance regularly using a visualization tool MadDash (Monitoring and Debugging Dashboard). “There are test transfers of 10 gigabytes of data, four times a day, among 25 organizations, so that’s roughly about 300 transfers four times a day. The reason why we picked that number, 10 gigabytes, was because that’s the amount of data you need to get TCP up to full speed,” says Smarr.
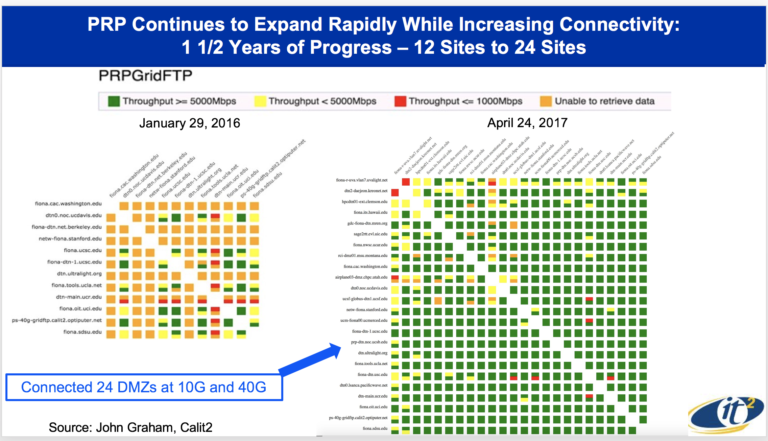
Networks are currently testing out at 5, 6, 7, 8 and 9 gigabits per second, which is nearly full utilization. “Some of them really nail it at 9.9 gigabits per second. If you go to 40 gigabit networks that we have, we are getting 13 and 14 gigabits per second and that’s because of the [constrained] software we are using. If we go to a different software, which is not what scientists routinely use [except] the high energy physics people, then we can get 30 or 40 or 100 gigabits per second – that’s where we max out with the PC architecture and the disk drives on those high end units,” explains DeFanti.
Like PRP before it, CHASE-CI is a response to an NSF call for community computer science infrastructure. Unlike PRP, which is focused on applications (e.g. geoscience, bioscience) and whose architecture was largely defined by guidance from domain scientists, CHASE-CI is being driven by needs of computer scientists trying to support big data and machine learning.
The full principal investigator team is an experienced and accomplished group including: Smarr, (Principal Investigator), Calit2; Tajana Rosing (Co-Principal Investigator), Professor, CSE Department, UCSD; Ilkay Altintas (Co-Principal Investigator), Chief Data Science Officer, San Diego Supercomputer Center; DeFanti (Co-Principal Investigator), Full Research Scientist at the UCSD Qualcomm Institute, a division of Calit2; and Kenneth Kreutz-Delgado (Co-Principal Investigator), Professor, ECE Department, UCSD.
“What they didn’t ask for [in the PRP grant] was what computer scientists need to support big data and machine learning. So we went back to the campuses and found the computers scientists, faculty and staff that were working on machine learning and ended up with 30 of them that wrote up their research to put into this proposal,” says Smarr. “We asked what was bottlenecking the work and [they responded] it was a lack of access to GPUs to do the compute intensive aspects of machine learning like training data sets on big neural nets.”
Zeroing in on GPUs, particularly GPUs that emphasize lower precision, is perhaps predictable.
“[In traditional] HPC you need 64-bit and error correction and all of that kind of stuff which is provided very nicely by Nvidia’s Tesla line, for instance, but actually because of the noise that is inherent in the data in most machine learning applications it turns out that single precision 32-bit is just fine and that’s much less expensive than the double precision,” says Smarr. For this reason, the project is focusing on less expensive “gaming GPUs” which fit fine into the slots on the FIONAs since they are PCs.
The NSF proposal first called for putting ten GPUs into each FIONA. “But we decided eight is probably optimal, eight of these front line game GPUs and we are deploying 32 of those FIONAs in this new grant across PRP to these researchers, and because they are all connected at 10 gigabits/s we can essentially treat them as a cloud,” says Smarr. There are ten campuses initially participating: UC San Diego, UC Berkeley, UC Irvine, UC Riverside, UC Santa Cruz, UC Merced, Sand Diego State University, Caltech, Stanford, and Montana State University (brief summary of researchers and their intended focus by campus is at the end of the article (taken from the grant proposal).

As shown in the cost comparison below, the premium for high end GPUs such as Nvidia P100 is dramatic. The CHASE-CI plan is to stick with commodity gaming GPUs, like the Nvidia 1080, since they are used in large volumes which keeps the prices down and the improvements coming. Nevertheless Smarr and DeFanti emphasize they are vendor agnostic and that other vendors have expressed interest in the program.
“Every year Nvidia comes out with a new set of devices and then halfway through the year they come out with an accelerated version so in some sense you are on a six month cycle. The game cards are around $600 and every year the [cost performance] gets better,” says DeFanti. “We buy what’s available, build, test, and benchmark and then we wait for the next round. [Notably], people in the community do have different needs – some need more memory, some would rather have twice as many $250 GPUs because they are really fast and just have less memory. So it is really kind of custom and there’s some negotiation with users, but they all fit in the same chassis.”
DeFanti argues the practice of simulating networks on CPUs has slowed machine learning’s growth. “Machine learning involves looking at gigabytes of data, millions of pictures, and basically doing that is a brute force calculation that works fine in 32 bit, nobody uses 64 bit. You chew on these things literally for a week even on a GPU, which is much faster than a CPU for these kind of these things. That’s a reason why this field was sort of sluggish just using simulators; it took too much time on desktop CPUs. The first phase of this revolution is getting everybody off simulators.”
That said, getting high performance GPUs into the hands of researchers and students is only half of the machine learning story. Training is hard and compute-intensive and can take weeks-to-months depending upon the problem. But once a network is trained, the computer power required for the inference engine is considerably less. Power consumption becomes the challenge particularly because these trained networks are expected to be widely deployed on mobile platforms.
Here, CHASE-CI is examining a wide range of device types and architectures. Calit2, for example, has been working with IBM’s neuromorphic True North chip for a couple of years. It also had a strong role in helping KnuEdge develop its DSP-based neural net chip. (KnuEdge, of course, was founded by former NASA administrator Daniel Goldin.) FPGAs also show promise.
Says Smarr, “They have got to be very energy efficient. You have this whole new generation of largely non von Neumann architectures that are capable of executing these machine learning algorithms on say streams of video data, radar data, LIDAR data, things like that, that make decisions in real time like approval on credit cards. We are building up a set of these different architectures – von Neumann and non von Neumann – and making those available to these 30 machine learning experts.”
[Editor's note: To read the rest of the original article, click here to view the complete report on the HPCwire website.]
Related Links
NSF Grant #1730158
Pacific Research Network
Qualcomm Institute
Calit2